Нормальное распределение имеет параметры. Нормальное распределение
Случайные величины связаны со случайными событиями. О случайных событиях говорят тогда, когда оказывается невозможным однозначно предсказать результат, который может быть получен в тех или иных условиях.
Предположим, мы бросаем обыкновенную монету. Обычно результат этой процедуры не является однозначно определенным. Можно лишь с уверенностью утверждать, что произойдет одно из двух: либо выпадет "орел", либо "решка". Любое из этих событий будет случайным. Можно ввести переменную, которая будет описывать исход этого случайного события. Очевидно, что эта переменная будет принимать два дискретных значения: "орел" и "решка". Поскольку мы заранее точно не можем предугадать, какое из двух возможных значений примет эта переменная, можно утверждать, что в этом случае мы имеем дело со случайными величинами.
Предположим теперь, что в эксперименте мы проводим оценку времени реакции испытуемого при предъявлении какого-либо стимула. Как правило, оказывается, что даже тогда, когда экспериментатор предпримет все меры к тому, чтобы стандартизировать экспериментальные условия, минимизировав или даже сведя к нулю возможные вариации в предъявлении стимула, измеренные величины времени реакции испытуемого все равно будут различаться. В таком случае говорят, что время реакции испытуемого описывается случайной величиной. Поскольку в принципе в эксперименте мы можем получить любое значение времени реакции – множество возможных значений времени реакции, которые можно получить в результате измерений, оказывается бесконечным, – говорят о непрерывности этой случайной величины.
Возникает вопрос: существуют ли какие-либо закономерности в поведении случайных величин? Ответ на этот вопрос оказывается утвердительным.
Так, если провести бесконечно большое число подбрасываний одной и той же монеты, можно обнаружить, что число выпадений каждой из двух сторон монеты окажется примерно одинаковым, если, конечно, монета не фальшивая и не гнутая. Чтобы подчеркнуть эту закономерность, вводят понятие вероятности случайного события. Ясно, что в случае с подбрасыванием монеты одно из двух возможных событий произойдет непременно. Это обусловлено тем, что суммарная вероятность этих двух событий, иначе называемая полной вероятностью, равна 100%. Если предположить, что оба из двух событий, связанных с испытанием монеты, происходят с равными долями вероятности, то вероятность каждого исхода в отдельности, очевидно, оказывается равной 50%. Таким образом, теоретические размышления позволяют нам описать поведение данной случайной величины. Такое описание в математической статистике обозначается термином "распределение случайной величины" .
Сложнее обстоит дело со случайной величиной, которая не имеет четко определенного набора значений, т.е. оказывается непрерывной. Но и в этом случае можно отметить некоторые важные закономерности ее поведения. Так, проводя эксперимент с измерением времени реакции испытуемого, можно отметить, что различные интервалы длительности реакции испытуемого оцениваются с разной степенью вероятности. Скорее всего, редко, когда испытуемый будет реагировать слишком быстро. Например, в задачах семантического решения испытуемым практически не удается более или менее точно реагировать со скоростью менее 500 мс (1/2 с). Аналогично маловероятно, что испытуемый, добросовестно следующий инструкциям экспериментатора, будет сильно затягивать свой ответ. В задачах семантического решения, например, реакции, оцениваемые более чем 5 с, обычно рассматриваются как недостоверные. Тем не менее со 100%-ной уверенностью можно предполагать, что время реакции испытуемого окажется в диапазоне от О до +со. Но эта вероятность складывается из вероятностей каждого отдельного значения случайной величины. Поэтому распределение непрерывной случайной величины можно описать в виде непрерывной функции у = f (х ).
Если мы имеем дело с дискретной случайной величиной, когда все возможные ее значения заранее известны, как в примере с монетой, построить модель ее распределения, как правило, оказывается не очень сложным. Достаточно ввести лишь некоторые разумные допущения, как мы это сделали в рассматриваемом примере. Сложнее обстоит дело с распределением непрерывных величии, принимающих заранее неизвестное число значений. Конечно, если бы мы, например, разработали теоретическую модель, описывающую поведение испытуемого в эксперименте с измерением времени реакции при решении задачи семантического решения, можно было бы попытаться на основе этой модели описать теоретическое распределение конкретных значений времени реакции одного и того же испытуемого при предъявлении одного и того же стимула. Однако такое не всегда оказывается возможным. Поэтому экспериментатор бывает вынужденным предположить, что распределение интересующей его случайной величины описывается каким-либо уже заранее исследованным законом. Чаще всего, хотя это, возможно, и не всегда оказывается абсолютно корректным, для этих целей используется так называемое нормальное распределение, выступающее в качестве эталона распределения любой случайной величины независимо от ее природы. Это распределение впервые было описано математически еще в первой половине XVIII в. де Муавром.
Нормальное распределение имеет место тогда, когда интересующее нас явление подвержено влиянию бесконечного числа случайных факторов, уравновешивающих друг друга. Формально нормальное распределение, как показал де Муавр, может быть описано следующим соотношением:
где х представляет собой интересующую нас случайную величину, поведение которой мы исследуем; Р – значение вероятности, связанное с этой случайной величиной; π и е – известные математические константы, описывающие соответственно отношение длины окружности к диаметру и основание натурального логарифма; μ и σ2 – параметры нормального распределения случайной величины – соответственно математическое ожидание и дисперсия случайной величины х.
Для описания нормального распределения оказывается необходимым и достаточным определение лишь параметров μ и σ2.
Поэтому если мы имеем случайную величину, поведение которой описывается уравнением (1.1) с произвольными значениями μ и σ2, то можем обозначить его как Ν (μ, σ2), не держа в памяти всех деталей этого уравнения.

Рис. 1.1.
Любое распределение можно представить наглядно в виде графика. Графически нормальное распределение имеет вид колоколообразной кривой, точная форма которой определяется параметрами распределения, т.е. математическим ожиданием и дисперсией. Параметры нормального распределения могут принимать практически любые значения, которые оказываются ограничены лишь используемой экспериментатором измерительной шкалой. В теории значение математического ожидания может равняться любому числу из диапазона чисел от -∞ до +∞, а дисперсия – любому неотрицательному числу. Поэтому существует бесконечное множество различных видов нормального распределения и соответственно бесконечное множество кривых, его представляющих (имеющих, однако, сходную колоколообразную форму). Понятно, что все их описать невозможно. Однако, если известны параметры конкретного нормального распределения, его можно преобразовать к так называемому единичному нормальному распределению, математическое ожидание для которого равно нулю, а дисперсия – единице. Такое нормальное распределение называют еще стандартным или z-распределением. График единичного нормального распределения представлен на рис. 1.1, откуда очевидно, что вершина колоколообразной кривой нормального распределения характеризует величину математического ожидания. Другой параметр нормального распределения – дисперсия – характеризует степень "распластанности" колоколообразной кривой относительно горизонтали (оси абсцисс).
Файл примераРассмотрим Нормальное распределение. С помощью функции MS EXCEL НОРМ.РАСП() построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел, распределенных по нормальному закону, произведем оценку параметров распределения, среднего значения и стандартного отклонения .
Нормальное распределение (также называется распределением Гаусса) является самым важным как в теории, так в приложениях системы контроля качества. Важность значения Нормального распределения (англ. Normal distribution ) во многих областях науки вытекает из теории вероятностей.
Определение : Случайная величина x распределена по нормальному закону , если она имеет :
Нормальное распределение зависит от двух параметров: μ (мю) - является , и σ ( сигма) - является (среднеквадратичным отклонением). Параметр μ определяет положение центра плотности вероятности нормального распределения , а σ - разброс относительно центра (среднего).
Примечание : О влиянии параметров μ и σ на форму распределения изложено в статье про , а в файле примера на листе Влияние параметров можно с помощью понаблюдать за изменением формы кривой.

Нормальное распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Нормального распределения имеется функция НОРМ.РАСП() , английское название - NORM.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и интегральную функцию распределения (вероятность, что случайная величина X, распределенная по нормальному закону , примет значение меньше или равное x). Вычисления в последнем случае производятся по следующей формуле:

Вышеуказанное распределение имеет обозначение N (μ; σ). Так же часто используют обозначение через N (μ; σ 2).
Примечание : До MS EXCEL 2010 в EXCEL была только функция НОРМРАСП() , которая также позволяет вычислить функцию распределения и плотность вероятности. НОРМРАСП() оставлена в MS EXCEL 2010 для совместимости.
Стандартное нормальное распределение
Стандартным нормальным распределением называется нормальное распределение с μ=0 и σ=1. Вышеуказанное распределение имеет обозначение N (0;1).
Примечание : В литературе для случайной величины, распределенной по стандартному нормальному закону, закреплено специальное обозначение z.
Любое нормальное распределение можно преобразовать в стандартное через замену переменной z =( x -μ)/σ . Этот процесс преобразования называется стандартизацией .
Примечание : В MS EXCEL имеется функция НОРМАЛИЗАЦИЯ() , которая выполняет вышеуказанное преобразование. Хотя в MS EXCEL это преобразование называется почему-то нормализацией . Формулы =(x-μ)/σ и =НОРМАЛИЗАЦИЯ(х;μ;σ) вернут одинаковый результат.
В MS EXCEL 2010 для имеется специальная функция НОРМ.СТ.РАСП() и ее устаревший вариант НОРМСТРАСП() , выполняющий аналогичные вычисления.
Продемонстрируем, как в MS EXCEL осуществляется процесс стандартизации нормального распределения N (1,5; 2).
Для этого вычислим вероятность, что случайная величина, распределенная по нормальному закону N(1,5; 2) , меньше или равна 2,5. Формула выглядит так: =НОРМ.РАСП(2,5; 1,5; 2; ИСТИНА) =0,691462. Сделав замену переменной z =(2,5-1,5)/2=0,5 , запишем формулу для вычисления Стандартного нормального распределения: =НОРМ.СТ.РАСП(0,5; ИСТИНА) =0,691462.
Естественно, обе формулы дают одинаковые результаты (см. файл примера лист Пример ).
Обратите внимание, что стандартизация относится только к (аргумент интегральная равен ИСТИНА), а не к плотности вероятности .
Примечание : В литературе для функции, вычисляющей вероятности случайной величины, распределенной по стандартному нормальному закону, закреплено специальное обозначение Ф(z). В MS EXCEL эта функция вычисляется по формуле =НОРМ.СТ.РАСП(z;ИСТИНА) . Вычисления производятся по формуле

В силу четности функции распределения f(x), а именно f(x)=f(-х), функция стандартного нормального распределения обладает свойством Ф(-x)=1-Ф(x).
Обратные функции
Функция НОРМ.СТ.РАСП(x;ИСТИНА) вычисляет вероятность P, что случайная величина Х примет значение меньше или равное х. Но часто требуется провести обратное вычисление: зная вероятность P, требуется вычислить значение х. Вычисленное значение х называется стандартного нормального распределения .
В MS EXCEL для вычисления квантилей используют функцию НОРМ.СТ.ОБР() и НОРМ.ОБР() .
Графики функций
В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения .
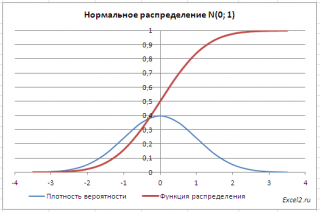
Как известно, около 68% значений, выбранных из совокупности, имеющей нормальное распределение , находятся в пределах 1 стандартного отклонения (σ) от μ(среднего или математического ожидания); около 95% - в пределах 2-х σ, а в пределах 3-х σ находятся уже 99% значений. Убедиться в этом для стандартного нормального распределения можно записав формулу:
= НОРМ.СТ.РАСП(1;ИСТИНА)-НОРМ.СТ.РАСП(-1;ИСТИНА)
которая вернет значение 68,2689% - именно такой процент значений находятся в пределах +/-1 стандартного отклонения от среднего (см. лист График в файле примера ).
В силу четности функции плотности стандартного нормального распределения: f ( x )= f (-х) , функция стандартного нормального распределения обладает свойством F(-x)=1-F(x). Поэтому, вышеуказанную формулу можно упростить:
= 2*НОРМ.СТ.РАСП(1;ИСТИНА)-1
Для произвольной функции нормального распределения N(μ; σ) аналогичные вычисления нужно производить по формуле:
2* НОРМ.РАСП(μ+1*σ;μ;σ;ИСТИНА)-1
Вышеуказанные расчеты вероятности требуются для .
Примечание : Для удобства написания формул в файле примера созданы для параметров распределения: μ и σ.
Генерация случайных чисел
Сгенерируем 3 массива по 100 чисел с различными μ и σ. Для этого в окне Генерация случайных чисел установим следующие значения для каждой пары параметров:
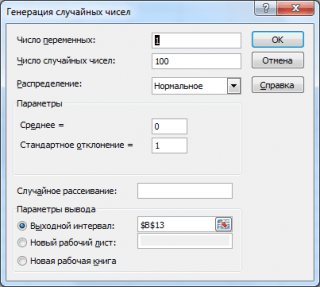
Примечание : Если установить опцию Случайное рассеивание ( Random Seed ), то можно выбрать определенный случайный набор сгенерированных чисел. Например, установив эту опцию равной 25, можно сгенерировать на разных компьютерах одни и те же наборы случайных чисел (если, конечно, другие параметры распределения совпадают). Значение опции может принимать целые значения от 1 до 32 767. Название опции Случайное рассеивание может запутать. Лучше было бы ее перевести как Номер набора со случайными числами .
В итоге будем иметь 3 столбца чисел, на основании которых можно, оценить параметры распределения, из которого была произведена выборка: μ и σ . Оценку для μ можно сделать с использованием функции СРЗНАЧ() , а для σ – с использованием функции СТАНДОТКЛОН.В() , см. .

Примечание : Для генерирования массива чисел, распределенных по нормальному закону , можно использовать формулу =НОРМ.ОБР(СЛЧИС();μ;σ) . Функция СЛЧИС() генерирует от 0 до 1, что как раз соответствует диапазону изменения вероятности (см. файл примера лист Генерация ).
Задачи
Задача1 . Компания изготавливает нейлоновые нити со средней прочностью 41 МПа и стандартным отклонением 2 МПа. Потребитель хочет приобрести нити с прочностью не менее 36 МПа. Рассчитайте вероятность, что партии нити, изготовленные компанией для потребителя, будут соответствовать требованиям или превышать их. Решение1 : = 1-НОРМ.РАСП(36;41;2;ИСТИНА)
Задача2 . Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Согласно техническим условиям, трубы признаются годными, если диаметр находится в пределах 20,00+/- 0,40 мм. Какая доля изготовленных труб соответствует ТУ? Решение2 : = НОРМ.РАСП(20,00+0,40;20,20;0,25;ИСТИНА)- НОРМ.РАСП(20,00-0,40;20,20;0,25) На рисунке ниже, выделена область значений диаметров, которая удовлетворяет требованиям спецификации.

Решение приведено в файле примера лист Задачи .
Задача3 . Предприятие изготавливает трубы, средний внешний диаметр которых равен 20,20 мм, а стандартное отклонение равно 0,25мм. Внешний диаметр не должен превышать определенное значение (предполагается, что нижняя граница не важна). Какую верхнюю границу в технических условиях необходимо установить, чтобы ей соответствовало 97,5% всех изготавливаемых изделий? Решение3 : = НОРМ.ОБР(0,975; 20,20; 0,25) =20,6899 или = НОРМ.СТ.ОБР(0,975)*0,25+20,2 (произведена «дестандартизация», см. выше)
Задача 4 . Нахождение параметров нормального распределения по значениям 2-х (или ). Предположим, известно, что случайная величина имеет нормальное распределение, но не известны его параметры, а только 2-я процентиля (например, 0,5- процентиль , т.е. медиана и 0,95-я процентиль ). Т.к. известна , то мы знаем , т.е. μ. Чтобы найти нужно использовать . Решение приведено в файле примера лист Задачи .
Примечание : До MS EXCEL 2010 в EXCEL были функции НОРМОБР() и НОРМСТОБР() , которые эквивалентны НОРМ.ОБР() и НОРМ.СТ.ОБР() . НОРМОБР() и НОРМСТОБР() оставлены в MS EXCEL 2010 и выше только для совместимости.
Линейные комбинации нормально распределенных случайных величин
Известно, что линейная комбинация нормально распределённых случайных величин x ( i ) с параметрами μ ( i ) и σ ( i ) также распределена нормально. Например, если случайная величина Y=x(1)+x(2), то Y будет иметь распределение с параметрами μ (1)+ μ(2) и КОРЕНЬ(σ(1)^2+ σ(2)^2). Убедимся в этом с помощью MS EXCEL.
(вещественный, строго положительный)
Норма́льное распределе́ние , также называемое распределением Гаусса или Гаусса - Лапласа - распределение вероятностей , которое в одномерном случае задаётся функцией плотности вероятности , совпадающей с функцией Гаусса :
f (x) = 1 σ 2 π e − (x − μ) 2 2 σ 2 , {\displaystyle f(x)={\frac {1}{\sigma {\sqrt {2\pi }}}}\;e^{-{\frac {(x-\mu)^{2}}{2\sigma ^{2}}}},}где параметр μ - математическое ожидание (среднее значение), медиана и мода распределения, а параметр σ - среднеквадратическое отклонение ( σ ² - дисперсия) распределения.
Таким образом, одномерное нормальное распределение является двухпараметрическим семейством распределений. Многомерный случай описан в статье «Многомерное нормальное распределение ».
Стандартным нормальным распределением называется нормальное распределение с математическим ожиданием μ = 0 и стандартным отклонением σ = 1 .
Энциклопедичный YouTube
-
1 / 5
Важное значение нормального распределения во многих областях науки (например, в математической статистике и статистической физике) вытекает из центральной предельной теоремы теории вероятностей . Если результат наблюдения является суммой многих случайных слабо взаимозависимых величин, каждая из которых вносит малый вклад относительно общей суммы, то при увеличении числа слагаемых распределение центрированного и нормированного результата стремится к нормальному. Этот закон теории вероятностей имеет следствием широкое распространение нормального распределения, что и стало одной из причин его наименования.
Свойства
Моменты
Если случайные величины X 1 {\displaystyle X_{1}} и X 2 {\displaystyle X_{2}} независимы и имеют нормальное распределение с математическими ожиданиями μ 1 {\displaystyle \mu _{1}} и μ 2 {\displaystyle \mu _{2}} и дисперсиями σ 1 2 {\displaystyle \sigma _{1}^{2}} и σ 2 2 {\displaystyle \sigma _{2}^{2}} соответственно, то X 1 + X 2 {\displaystyle X_{1}+X_{2}} также имеет нормальное распределение с математическим ожиданием μ 1 + μ 2 {\displaystyle \mu _{1}+\mu _{2}} и дисперсией σ 1 2 + σ 2 2 . {\displaystyle \sigma _{1}^{2}+\sigma _{2}^{2}.} Отсюда вытекает, что нормальная случайная величина представима как сумма произвольного числа независимых нормальных случайных величин.
Максимальная энтропия
Нормальное распределение имеет максимальную дифференциальную энтропию среди всех непрерывных распределений, дисперсия которых не превышает заданную величину .
Моделирование нормальных псевдослучайных величин
Простейшие приближённые методы моделирования основываются на центральной предельной теореме . Именно, если сложить несколько независимых одинаково распределённых величин с конечной дисперсией , то сумма будет распределена приблизительно нормально. Например, если сложить 100 независимых стандартно равномерно распределённых случайных величин, то распределение суммы будет приближённо нормальным .
Для программного генерирования нормально распределённых псевдослучайных величин предпочтительнее использовать преобразование Бокса - Мюллера . Оно позволяет генерировать одну нормально распределённую величину на базе одной равномерно распределённой.
Нормальное распределение в природе и приложениях
Нормальное распределение часто встречается в природе. Например, следующие случайные величины хорошо моделируются нормальным распределением:
- отклонение при стрельбе.
- погрешности измерений (однако погрешности некоторых измерительных приборов имеют не нормальные распределения).
- некоторые характеристики живых организмов в популяции.
Такое широкое распространение этого распределения связано с тем, что оно является бесконечно делимым непрерывным распределением с конечной дисперсией. Поэтому к нему в пределе приближаются некоторые другие, например, биномиальное и пуассоновское . Этим распределением моделируются многие не детерминированные физические процессы.
Связь с другими распределениями
- Нормальное распределение является распределением Пирсона типа XI .
- Отношение пары независимых стандартных нормально распределенных случайных величин имеет распределение Коши . То есть, если случайная величина X {\displaystyle X} представляет собой отношение X = Y / Z {\displaystyle X=Y/Z} (где Y {\displaystyle Y} и Z {\displaystyle Z} - независимые стандартные нормальные случайные величины), то она будет обладать распределением Коши.
- Если z 1 , … , z k {\displaystyle z_{1},\ldots ,z_{k}} - совместно независимые стандартные нормальные случайные величины, то есть z i ∼ N (0 , 1) {\displaystyle z_{i}\sim N\left(0,1\right)} , то случайная величина x = z 1 2 + … + z k 2 {\displaystyle x=z_{1}^{2}+\ldots +z_{k}^{2}} имеет распределение хи-квадрат с k степенями свободы.
- Если случайная величина X {\displaystyle X} подчинена логнормальному распределению , то её натуральный логарифм имеет нормальное распределение. То есть, если X ∼ L o g N (μ , σ 2) {\displaystyle X\sim \mathrm {LogN} \left(\mu ,\sigma ^{2}\right)} , то Y = ln (X) ∼ N (μ , σ 2) {\displaystyle Y=\ln \left(X\right)\sim \mathrm {N} \left(\mu ,\sigma ^{2}\right)} . И наоборот, если Y ∼ N (μ , σ 2) {\displaystyle Y\sim \mathrm {N} \left(\mu ,\sigma ^{2}\right)} , то X = exp (Y) ∼ L o g N (μ , σ 2) {\displaystyle X=\exp \left(Y\right)\sim \mathrm {LogN} \left(\mu ,\sigma ^{2}\right)} .
- Отношение квадратов двух стандартных нормальных случайных величин имеет имеет
Нормальный закон распределения вероятностей
Без преувеличения его можно назвать философским законом. Наблюдая за различными объектами и процессами окружающего мира, мы часто сталкиваемся с тем, что чего-то бывает мало, и что бывает норма:

Перед вами принципиальный вид функции плотности нормального распределения вероятностей, и я приветствую вас на этом интереснейшем уроке.Какие можно привести примеры? Их просто тьма. Это, например, рост, вес людей (и не только), их физическая сила, умственные способности и т.д. Существует «основная масса» (по тому или иному признаку) и существуют отклонения в обе стороны.
Это различные характеристики неодушевленных объектов (те же размеры, вес). Это случайная продолжительность процессов, например, время забега стометровки или превращения смолы в янтарь. Из физики вспомнились молекулы воздуха: среди них есть медленные, есть быстрые, но большинство двигаются со «стандартными» скоростями.
Далее отклоняемся от центра ещё на одно стандартное отклонение и рассчитываем высоту:

Отмечаем точки на чертеже (зелёный цвет) и видим, что этого вполне достаточно.
На завершающем этапе аккуратно чертим график, и особо аккуратно отражаем его выпуклость / вогнутость ! Ну и, наверное, вы давно поняли, что ось абсцисс – это горизонтальная асимптота , и «залезать» за неё категорически нельзя!
При электронном оформлении решения график легко построить в Экселе, и неожиданно для самого себя я даже записал короткий видеоролик на эту тему. Но сначала поговорим о том, как меняется форма нормальной кривой в зависимости от значений и .
При увеличении или уменьшении «а» (при неизменном «сигма») график сохраняет свою форму и перемещается вправо / влево соответственно. Так, например, при функция принимает вид
 и наш график «переезжает» на 3 единицы влево – ровнехонько в начало координат:
и наш график «переезжает» на 3 единицы влево – ровнехонько в начало координат:
Нормально распределённая величина с нулевым математическим ожиданием получила вполне естественное название – центрированная ; её функция плотности – чётная , и график симметричен относительно оси ординат.В случае изменения «сигмы» (при постоянном «а») , график «остаётся на месте», но меняет форму. При увеличении он становится более низким и вытянутым, словно осьминог, растягивающий щупальца. И, наоборот, при уменьшении график становится более узким и высоким – получается «удивлённый осьминог». Так, при уменьшении «сигмы» в два раза: предыдущий график сужается и вытягивается вверх в два раза:

Всё в полном соответствии с геометрическими преобразованиями графиков .Нормальное распределёние с единичным значением «сигма» называется нормированным , а если оно ещё и центрировано (наш случай), то такое распределение называют стандартным . Оно имеет ещё более простую функцию плотности, которая уже встречалась в локальной теореме Лапласа :
 . Стандартное распределение нашло широкое применение на практике, и очень скоро мы окончательно поймём его предназначение.
. Стандартное распределение нашло широкое применение на практике, и очень скоро мы окончательно поймём его предназначение.Ну а теперь смотрим кино:
Да, совершенно верно – как-то незаслуженно у нас осталась в тени функция распределения вероятностей . Вспоминаем её определение :
– вероятность того, что случайная величина примет значение, МЕНЬШЕЕ, чем переменная , которая «пробегает» все действительные значения до «плюс» бесконечности.Внутри интеграла обычно используют другую букву, чтобы не возникало «накладок» с обозначениями, ибо здесь каждому значению ставится в соответствие несобственный интеграл , который равен некоторому числу из интервала .
Почти все значения не поддаются точному расчету, но как мы только что видели, с современными вычислительными мощностями с этим нет никаких трудностей. Так, для функции стандартного распределения соответствующая экселевская функция вообще содержит один аргумент:
=НОРМСТРАСП(z)
Раз, два – и готово:

На чертеже хорошо видно выполнение всех свойств функции распределения , и из технических нюансов здесь следует обратить внимание на горизонтальные асимптоты и точку перегиба .Теперь вспомним одну из ключевых задач темы, а именно выясним, как найти –вероятность того, что нормальная случайная величина примет значение из интервала . Геометрически эта вероятность равна площади между нормальной кривой и осью абсцисс на соответствующем участке:

но каждый раз вымучивать приближенное значение неразумно, и поэтому здесь рациональнее использовать «лёгкую» формулу
:
неразумно, и поэтому здесь рациональнее использовать «лёгкую» формулу
:
.! Вспоминает также , что
Тут можно снова задействовать Эксель, но есть пара весомых «но»: во-первых, он не всегда под рукой, а во-вторых, «готовые» значения , скорее всего, вызовут вопросы у преподавателя. Почему?
Об этом я неоднократно рассказывал ранее: в своё время (и ещё не очень давно) роскошью был обычный калькулятор, и в учебной литературе до сих пор сохранился «ручной» способ решения рассматриваемой задачи. Его суть состоит в том, чтобы стандартизировать значения «альфа» и «бета», то есть свести решение к стандартному распределению:

Примечание : функцию легко получить из общего случая
 с помощью линейной замены
. Тогда и:
с помощью линейной замены
. Тогда и:
и из проведённой замены как раз следует формула перехода от значений произвольного распределения – к соответствующим значениям стандартного распределения.Зачем это нужно? Дело в том, что значения скрупулезно подсчитаны нашими предками и сведены в специальную таблицу, которая есть во многих книгах по терверу. Но ещё чаще встречается таблица значений , с которой мы уже имели дело в интегральной теореме Лапласа :
Если же в нашем распоряжении есть таблица значений функции Лапласа
 , то решаем через неё:
, то решаем через неё:
Дробные значения традиционно округляем до 4 знаков после запятой, как это сделано в типовой таблице. И для контроля есть Пункт 5 макета .Напоминаю, что , и во избежание путаницы всегда контролируйте , таблица КАКОЙ функции перед вашими глазами.
Ответ требуется дать в процентах, поэтому рассчитанную вероятность нужно умножить на 100 и снабдить результат содержательным комментарием:
– с перелётом от 5 до 70 м упадёт примерно 15,87% снарядов
Тренируемся самостоятельно:
Пример 3
Диаметр подшипников, изготовленных на заводе, представляет собой случайную величину, распределенную нормально с математическим ожиданием 1,5 см и средним квадратическим отклонением 0,04 см. Найти вероятность того, что размер наугад взятого подшипника колеблется от 1,4 до 1,6 см.
В образце решения и далее я буду использовать функцию Лапласа, как самый распространённый вариант. Кстати, обратите внимание, что согласно формулировке, здесь можно включить концы интервала в рассмотрение. Впрочем, это не критично.
И уже в этом примере нам встретился особый случай – когда интервал симметричен относительно математического ожидания. В такой ситуации его можно записать в виде и, пользуясь нечётностью функции Лапласа, упростить рабочую формулу:

Параметр «дельта» называют отклонением от математического ожидания, и двойное неравенство можно «упаковывать» с помощью модуля :– вероятность того, что значение случайной величины отклонится от математического ожидания менее чем на .
Хорошо то решение, которое умещается в одну строчку:)
– вероятность того, что диаметр наугад взятого подшипника отличается от 1,5 см не более чем на 0,1 см.Результат этой задачи получился близким к единице, но хотелось бы ещё бОльшей надежности – а именно, узнать границы, в которых находится диаметр почти всех подшипников. Существует ли какой-нибудь критерий на этот счёт? Существует! На поставленный вопрос отвечает так называемое
правило «трех сигм»
Его суть состоит в том, что практически достоверным является тот факт, что нормально распределённая случайная величина примет значение из промежутка
 .
.И в самом деле, вероятность отклонения от матожидания менее чем на составляет:
или 99,73%В «пересчёте на подшипники» – это 9973 штуки с диаметром от 1,38 до 1,62 см и всего лишь 27 «некондиционных» экземпляров.
В практических исследованиях правило «трёх сигм» обычно применяют в обратном направлении: если статистически установлено, что почти все значения исследуемой случайной величины укладываются в интервал длиной 6 стандартных отклонений, то появляются веские основания полагать, что эта величина распределена по нормальному закону. Проверка осуществляется с помощью теории статистических гипотез .
Продолжаем решать суровые советские задачи:
Пример 4
Случайная величина ошибки взвешивания распределена по нормальному закону с нулевым математическим ожиданием и стандартным отклонением 3 грамма. Найти вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей по модулю 5 грамм.
Решение очень простое. По условию, и сразу заметим, что при очередном взвешивании (чего-то или кого-то) мы почти 100% получим результат с точностью до 9 грамм. Но в задаче фигурирует более узкое отклонение и по формуле :
 – вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей 5 грамм.
– вероятность того, что очередное взвешивание будет проведено с ошибкой, не превышающей 5 грамм.Ответ :
Прорешанная задача принципиально отличается от вроде бы похожего Примера 3 урока о равномерном распределении . Там была погрешность округления результатов измерений, здесь же речь идёт о случайной погрешности самих измерений. Такие погрешности возникают в связи с техническими характеристиками самого прибора (диапазон допустимых ошибок, как правило, указывают в его паспорте) , а также по вине экспериментатора – когда мы, например, «на глазок» снимаем показания со стрелки тех же весов.
Помимо прочих, существуют ещё так называемые систематические ошибки измерения. Это уже неслучайные ошибки, которые возникают по причине некорректной настройки или эксплуатации прибора. Так, например, неотрегулированные напольные весы могут стабильно «прибавлять» килограмм, а продавец систематически обвешивать покупателей. Или не систематически ведь можно обсчитать. Однако, в любом случае, случайной такая ошибка не будет, и её матожидание отлично от нуля.
…срочно разрабатываю курс по подготовке продавцов =)
Самостоятельно решаем обратную задачу:
Пример 5
Диаметр валика – случайная нормально распределенная случайная величина, среднее квадратическое отклонение ее равно мм. Найти длину интервала, симметричного относительно математического ожидания, в который с вероятностью попадет длина диаметра валика.
Пункт 5* расчётного макета в помощь. Обратите внимание, что здесь не известно математическое ожидание, но это нисколько не мешает решить поставленную задачу.
И экзаменационное задание, которое я настоятельно рекомендую для закрепления материала:
Пример 6
Нормально распределенная случайная величина задана своими параметрами (математическое ожидание) и (среднее квадратическое отклонение). Требуется:
а) записать плотность вероятности и схематически изобразить ее график;
б) найти вероятность того, что примет значение из интервала ;
;
в) найти вероятность того, что отклонится по модулю от не более чем на ;
г) применяя правило «трех сигм», найти значения случайной величины .Такие задачи предлагаются повсеместно, и за годы практики мне их довелось решить сотни и сотни штук. Обязательно попрактикуйтесь в ручном построении чертежа и использовании бумажных таблиц;)
Ну а я разберу пример повышенной сложности:
Пример 7
Плотность распределения вероятностей случайной величины имеет вид
 . Найти , математическое ожидание , дисперсию , функцию распределения , построить графики плотности и функции распределения, найти .
. Найти , математическое ожидание , дисперсию , функцию распределения , построить графики плотности и функции распределения, найти .Решение : прежде всего, обратим внимание, что в условии ничего не сказано о характере случайной величины. Само по себе присутствие экспоненты ещё ничего не значит: это может оказаться, например, показательное или вообще произвольное непрерывное распределение . И поэтому «нормальность» распределения ещё нужно обосновать:
Так как функция
 определена при любом
действительном значении , и её можно привести к виду , то случайная величина распределена по нормальному закону.
определена при любом
действительном значении , и её можно привести к виду , то случайная величина распределена по нормальному закону.Приводим. Для этого выделяем полный квадрат и организуем трёхэтажную дробь :

Обязательно выполняем проверку, возвращая показатель в исходный вид:
, что мы и хотели увидеть.Таким образом:
 – по правилу действий со степенями
«отщипываем» . И здесь можно сразу записать очевидные числовые характеристики:
– по правилу действий со степенями
«отщипываем» . И здесь можно сразу записать очевидные числовые характеристики:Теперь найдём значение параметра . Поскольку множитель нормального распределения имеет вид и , то:
 , откуда выражаем и подставляем в нашу функцию:
, откуда выражаем и подставляем в нашу функцию: , после чего ещё раз пробежимся по записи глазами и убедимся, что полученная функция имеет вид
, после чего ещё раз пробежимся по записи глазами и убедимся, что полученная функция имеет вид  .
.Построим график плотности:

и график функции распределения :
:
Если под рукой нет Экселя и даже обычного калькулятора, то последний график легко строится вручную! В точке функция распределения принимает значение и здесь находитсяЗакон нормального распределения, так называемый закон Гаусса - один из самых распространенных законов. Это фундаментальный закон в теории вероятностей и в ее применении. Нормальное распределение чаще всего встречается в изучении природных и социально-экономических явлений. Иначе говоря, большинство статистических совокупностей в природе и обществе подчиняется закону нормального распределения. Соответственно можно сказать, что совокупности большого числа крупных по объему выборок подчиняются закону нормального распределения. Те из совокупностей, которые отклоняются от нормального распределения в результате специальных преобразований, могут быть приближены к нормальному. В связи с этим следует помнить, что принципиальная особенность этого закона применительно к другим законам распределения заключается в том, что он является законом границы, к которой приближаются другие законы распределения в определенных (типовых) условиях.
Следует отметить, что термин "нормальное распределение" имеет условный смысл, как общепринятый в математической и статистико-математической литературе термин. Утверждение, что тот или иной признак любого явления подчиняется закону нормального распределения, вовсе не означает незыблемость норм, будто присущих исследуемому явлению, а отнесения последнего ко второму виду закона не означает какую-то анормальнисть данного явления. В этом смысле термин "нормальное распределение" не совсем удачен.
Нормальное распределение (закон Гаусса-Лапласа) является типом непрерывного распределения. Где Муавр (одна тысяча семьсот семьдесят три, Франция) вывел нормальный закон распределения вероятностей. Основные идеи этого открытия были использованы в теории ошибок впервые К. Гауссом (1809, Германия) и А.Лапласом (1812, Франция), которые внесли витчутний теоретический вклад в разработку самого закона. В частности, К. Гаусс в своих разработках исходил из признания наиболее вероятным значением случайной величины-среднюю арифметическую. Общие условия возникновения нормального распределения установил А.М.Ляпунова. Им было доказано, что если исследуемая признак представляет собой результат суммарного воздействия многих факторов, каждый из которых мало связан с большинством остальных, и влияние каждого фактора на конечный результат гораздо перекрывается суммарным воздействием всех остальных факторов, то распределение становится близким к нормальному.
Нормальным называют распределение вероятностей непрерывной случайной величины, имеет плотность:
1 +1 (& #) 2
/ (х, х, <т) = - ^ е 2 ст2
где х - математическое ожидание или средняя величина. Как видно, нормальное распределение определяется двумя параметрами: х и °. Чтобы задать нормальное распределение, достаточно знать математическое ожидание или среднее и среднее квадратическое отклонение. Эти две величины определяют центр группировки и форму
кривой на графике. График функции и (хх, в) называется нормальной кривой (кривая Гаусса) с параметрами х и в (рис. 12).
Кривая нормального распределения имеет точки перегиба при X ± 1. Если представить графически, то между X = + l и 1 = -1 находится 0,683 части всей площади кривой (т.е. 68,3%). В границах X = + 2 и X- 2. находятся 0,954 площади (95,4%), а между X = + 3 и X = - 3 - 0,997 части всей площади распределения (99,7%). На рис. 13 проиллюстрирован характер нормального распределения с одно-, двух- и трисигмовою границами.
При нормальном распределении средняя арифметическая, мода и медиана будут равны между собой. Форма нормальной кривой имеет вид одновершинные симметричной кривой, ветки которой асимптотически приближаются к оси абсцисс. Наибольшая ордината кривой соответствует х = 0. В этой точке на оси абсцисс размещается численное значение признаков, равное средней арифметической, моде и медиане. По обе стороны от вершины кривой ее ветки приходят, изменяя в определенных точках форму выпуклости на вогнутость. Эти точки симметричные и соответствуют значениям х = ± 1, то есть величинам признаки, отклонения которых от средней численно равна среднему квадратичному отклонению. Ордината, что соответствует средней арифметической, делит всю площадь между кривой и осью абсцисс пополам. Итак, вероятности появления значений исследуемого признака больших и меньших средней
арифметической будут равны 0,50, то есть х, (~ ^ х) = 0,50 В
Рис.12. Кривая нормального распределения (кривая Гаусса)
Форму и положение нормальной кривой обусловливают значение средней и среднего квадратичного отклонения. Математически доказано, что изменение величины среднего (математического ожидания) не изменяет формы нормальной кривой, а приводит лишь к ее смещение вдоль оси абсцисс. Кривая сдвигается вправо, если ~ растет, и влево, если ~ приходит.

Рис.14. Кривые нормального распределения с различными значениями параметра в
Об изменении формы графика нормальной кривой при изменении
среднего квадратичного отклонения можно судить по максимуму
дифференциальной функции нормального распределения, равный 1
Как видно, при росте величины ° максимальная ордината кривой будет уменьшаться. Следовательно, кривая нормального распределения будет сжиматься к оси абсцисс и принимать более плосковершинных форму.
И, наоборот, при уменьшении параметра в нормальная кривая вытягивается в положительном направлении оси ординат, а форма "колокола" становится более гостровершиною (рис. 14). Отметим, что независимо от величины параметров ~ и в площадь, ограниченная осью абсцисс и кривой, всегда равен единице (свойство плотности распределения). Это наглядно иллюстрирует график (рис. 13).
Названные выше особенности проявления "нормальности" распределения позволяют выделить ряд общих свойств, которые имеют кривые нормального распределения:
1) любой нормальный кривая достигает точки максимума (х = х) приходит непрерывно вправо и влево от него, постепенно приближаясь к оси абсцисс;
2) любой нормальный кривая симметрична по отношению к прямой,
параллельной оси ординат и проходит через точку максимума (х = х)
максимальная ордината равна ^^^ я;
3) любой нормальный кривая имеет форму "колокола", имеет выпуклость, которая направлена вверх к точке максимума. В точках х ~ ° и х + в она меняет выпуклость, и, чем меньше а, тем острее "колокол", а чем больше а, тем более похилишою становится вершина "колокола" (рис.14). Изменение математического ожидания (при неизменной величине
в) не приводит к модификации формы кривой.
При х = 0 и ° = 1 нормальную кривую называют нормированной кривой или нормальным распределением в каноническом виде.
Нормированная кривая описывается следующей формуле:
Построение нормальной кривой по эмпирическим данным производится по формуле:
пи 1 - "" = --- 7 = е
где и ™ - теоретическая частота каждого интервала (группы) распределения; "- Сумма частот, равную объему совокупности; "- шаг интервала;
же - отношение длины окружности к ее диаметру, которое составляет
е - основание натуральных логарифмов, равна 2,71828;
Вторая и третья части формулы) является функцией
нормированного отклонения ЦЧ), которую можно рассчитать для любых значений X. Таблицы значений ЦЧ) обычно называют "таблицы ординат нормальной кривой" (приложение 3). При использовании этих функций рабочая формула нормального распределения приобретает простого вида:
Пример. Рассмотрим случай построения нормальной кривой на примере данных о распределении 57 работников по уровню дневного заработка (табл. 42). По данным таблицы 42, находим среднюю арифметическую:
~ = ^ = И6 54 =
Рассчитываем среднее квадратическое отклонение:
Для каждой строки таблицы находим значение нормированного отклонения
х и ~ х | 12 г => - = - ^ 2 = 1.92
а 6.25 (дд Я первого интервала и т.д.).
В графе 8 табл. 42 записываем табличное значение функции Ди) из приложения, например, для первого интервала X = 1.92 находим "1,9" против "2" (0.0632).
Для вычисления теоретических частот, то есть ординат кривой нормального распределения, вычисляется множитель:
* = ^ = 36,5 а 6,25
Все найденные табличные значения функции / (г) умножаем на 36,5. Так, для первого интервала получаем 0,0632x36,5 = 2,31 т. Принято немногочисленные
частоты (п "<5) объединять (в нашем примере - первые два и последние два интервала).
Если крайние теоретические частоты значительно отличаются от нуля, расхождение между суммами эмпирических и теоретических частот может оказаться значительной.
График распределения эмпирических и теоретических частот (нормальная кривая) по данным рассматриваемого примера показано на рисунке 15.
Рассмотрим пример определения частот нормального распределения для случая, когда в крайних интервалах отсутствует частота (табл. 43). Здесь эмпирическая
X - нормированное отклонение, (в) а - среднее квадратическое отклонение.
частота первого интервала равна нулю. Полученная сумма неуточненных частот не равна сумме их эмпирических значений (56 * 57). В этом случае рассчитывается теоретическая частота для умывания полученных значений центра интервала, нормированного отклонения и его функции.
В таблице 43 эти величины обведено прямоугольником. При построении графика нормальной кривой в таких случаях теоретическую кривую продолжают. В рассматриваемом случае нормальная кривая будет продолжена в сторону отрицательных отклонений от средней, поскольку первая не уточнена частота равна 5. Рассчитана теоретическая частота (уточненная) для первого интервала будет равен единице. По сумме уточнены частоты совпадают с эмпирическими
Таблица 42
Расчетные величины
Статистические параметры
Интервал,
Количество единиц,
х) 2 n¡
нормированное отделения,
теоретическая
частота нормального ряда распределения,
/ 0) х - а
>>
Тысяча шестьсот пятьдесят четыре
а = 6,25
^ i = 36,5 а
Таблица 43
Расчет частот нормального распределения (выравнивание эмпирических частот по нормальному закону)
Количество единиц,
Расчетные величины
Статистические параметры
Интервал (и-2)
Срединное значение (центр) интервала,
(je, -xf
^ x t -x) 1 n и
нормированное отклонение
x s - х
t = x --L
табличное значение функции, f (t)
теоретическая
частота нормального ряда распределения
уточненное значение теоретической частоты,
ш
-
-
-
-
-
о = 2,41

Рис. 15. Эмпирический распределение (1) и нормальная кривая (2)
Кривую нормального распределения по исследуемой совокупности можно построить и другим способом (в отличие, от рассмотренного выше). Так, если необходимо иметь приближенную представление о соответствии фактического распределения нормальному, вычисления осуществляют следующим последовательности. Определяют максимальную ординату, которая соответствует среднему размеру признаки), затем, вычислив среднее квадратическое отклонение, рассчитывают координаты точек кривой нормального распределения по схеме, изложенной в таблицах 42 и 43. Так, по исходным и расчетным данным таблицы 43 должны среднюю ~ = 26 Эта величина средней совпадает с центром четвертого интервала (25-27). Итак, частота этого интервала "20" может быть принята (при построении графика) максимальной ординату). Имея исчисленную дисперсию (в = 2,41 см. Табл. 43), рассчитываем значения координат всех необходимых точек кривой нормального распределения (табл. 44, 45). По полученным координатам чертим нормальную кривую (рис. 16), приняв максимальной ординату частоту четвертого интервала.
Согласованность эмпирического распределения с нормальным может быть установлена также путем упрощенных расчетов. Так, если отношение показателя степени асимметрии (^) к своей середнеквадраты-ческой ошибки ш а "или отношение показателя эксцесса (Е х) к своей среднеквадратического ошибки т & превышает по абсолютной величине число« 3 », делается вывод о несоответствии эмпирического распределения характера нормального распределения (то есть,
А ц Е х
если ™ А> 3 или ш е "> 3).
Есть и другие, нетрудоемкие приемы установления "нормальности" распределения: а) сравнение средней арифметической с модой и медианой; б) использование цифр Вестергард; в) применение графического образа с помощью полулогарифмическая сетки Турбина; г) вычисление специальных критериев согласования и др.
Таблица 44
Координаты 7 точек кривой нормального распределения
Таблица 45
Вычисление координат точек кривой нормального распределения
x - 1,5 (7 =
х - а = 23,6
х - 0,5 (7 = = 24,8
х + 0,5ст = 27,2
х + а = 28,4
X + 1,5 (7 =

Рис.16. Кривая нормального распределения, построенная по семи точках
На практике при исследовании совокупности на предмет согласования ее распределения с нормальным часто пользуются "правилом 3сг".
Математически доказано вероятность того, что отклонение от средней по абсолютной величине будет меньше тройного среднего квадратичного отклонения, равно 0,9973, то есть, вероятность того, что абсолютная величина отклонения превышает тройное среднее квадратическое отклонение, равна 0,0027 или очень мала. Исходя из принципа невозможности маловероятных событий, можно считать практически невозможным "случай превышения" 3 ст. Если случайная величина распределена нормально, то абсолютная величина ее отклонения от математического ожидания (средней) не превышает тройного среднего квадратичного отклонения.
В практических расчетах действуют таким образом. Если при неизвестном характере распределения исследуемой случайной величины рассчитанное значение отклонения от средней окажется меньше значения 3 СТ, то есть основания полагать, что исследуемая признак распределена нормально. Если же указанный параметр превысит числовое значение 3 СТ, можно считать, что распределение исследуемой величины не согласуется с нормальным распределением.
Вычисления теоретических частот для исследуемого эмпирического ряда распределения принято называть выравниванием эмпирических кривых по нормальному (или любом другом) закона распределения. Этот процесс имеет важное как теоретическое, так практическое значение. Выравнивание эмпирических данных раскрывает закономерность в их распределении, которая может быть завуалирована случайной формой своего проявления. Установленную таким образом закономерность можно использовать для решения ряда практических задач.
С распределением, близким к нормальному, исследователь встречается в различных сферах науки и областях практической деятельности человека. В экономике такого рода распределения встречаются реже, чем, скажем, в технике или биологии. Обусловлено это самой природой социально-экономических явлений, которые характеризуются большой сложностью взаимосвязанных и взаимосвязанных факторов, а также наличием ряда условий, ограничивающих свободную "игру" случаев. Но экономист должен обращаться к нормальному распределению, анализируя строение эмпирических распределений, как к некоторому эталону. Такое сравнение позволяет выяснить характер тех внутренних условий, которые определяют данную фигуру распределения.
Проникновение сферы статистических исследований в область социально-экономических явлений позволило раскрыть существование большого количества различного типа кривых распределения. Однако не надо считать, что теоретическая концепция кривой нормального распределения вообще мало пригодна в статистико-математическом анализе такого типа явлений. Она может быть не всегда приемлема в анализе конкретного статистического распределения, но в области теории и практики выборочного метода исследования имеет первостепенное значение.
Назовем основные аспекты применения нормального распределения в статистико-математическом анализе.
1. Для определения вероятности конкретного значения признака. Это необходимо при проверке гипотез о соответствии того или иного эмпирического распределения нормальному.
2. При оценке ряда параметров, например, средних, методом максимального правдоподобия. Суть его заключается в определении такого закона, которому подчиняется совокупность. Определяется и оценка, которая дает максимальные значения. Лучшее приближение к параметрам генеральной совокупности дает отношение:
у = - 2 = е 2
3. Для определения вероятности выборочных средних относительно генеральных средних.
4. При определении доверительного интервала, в котором находится приближенное значение характеристик генеральной совокупности.